WACV 2026
Uncurated results from Learn-to-Steer. The approach easily generates spatially aligned images.
Green boxes mark aligned images, while misaligned ones are in red (per the GenEval benchmark).







Text-to-image diffusion models can generate stunning visuals, yet they often fail at tasks children find trivial—like placing a dog to the right of a teddy bear rather than to the left. When combinations get more unusual—a giraffe above an airplane—these failures become even more pronounced. Existing methods attempt to fix these spatial reasoning failures through model fine-tuning or test-time optimization with handcrafted losses that are suboptimal. Rather than imposing our assumptions about spatial encoding, we propose learning these objectives directly from the model's internal representations.
We introduce Learn-to-Steer, a novel framework that learns data-driven objectives for test-time optimization rather than handcrafting them. Our key insight is to train a lightweight classifier that decodes spatial relationships from the diffusion model's cross-attention maps, then deploy this classifier as a learned loss function during inference. Training such classifiers poses a surprising challenge: they can take shortcuts by detecting linguistic traces rather than learning true spatial patterns. We solve this with a dual-inversion strategy that enforces geometric understanding.
Our method dramatically improves spatial accuracy: from 0.20 to 0.61 on FLUX.1-dev and from 0.07 to 0.54 on SD2.1 across standard benchmarks. Moreover, our approach generalizes to multiple relations and significantly improves accuracy.
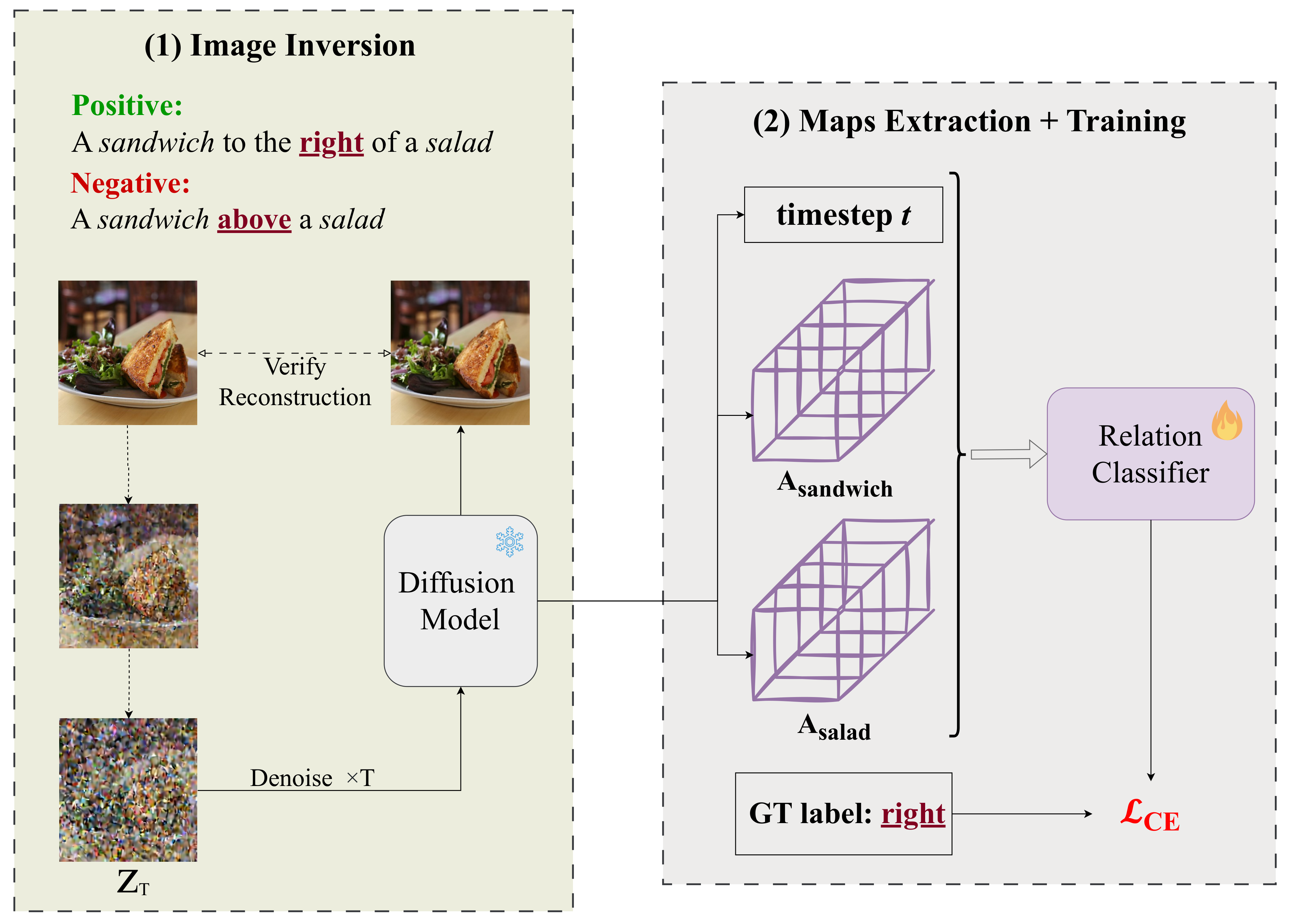
Training Pipeline
Given a spatially-aligned image, we perform dual image inversion (positive and negative prompts) to prevent relation leakage. During denoising, we extract the relevant attention maps and use them to train our classifier.
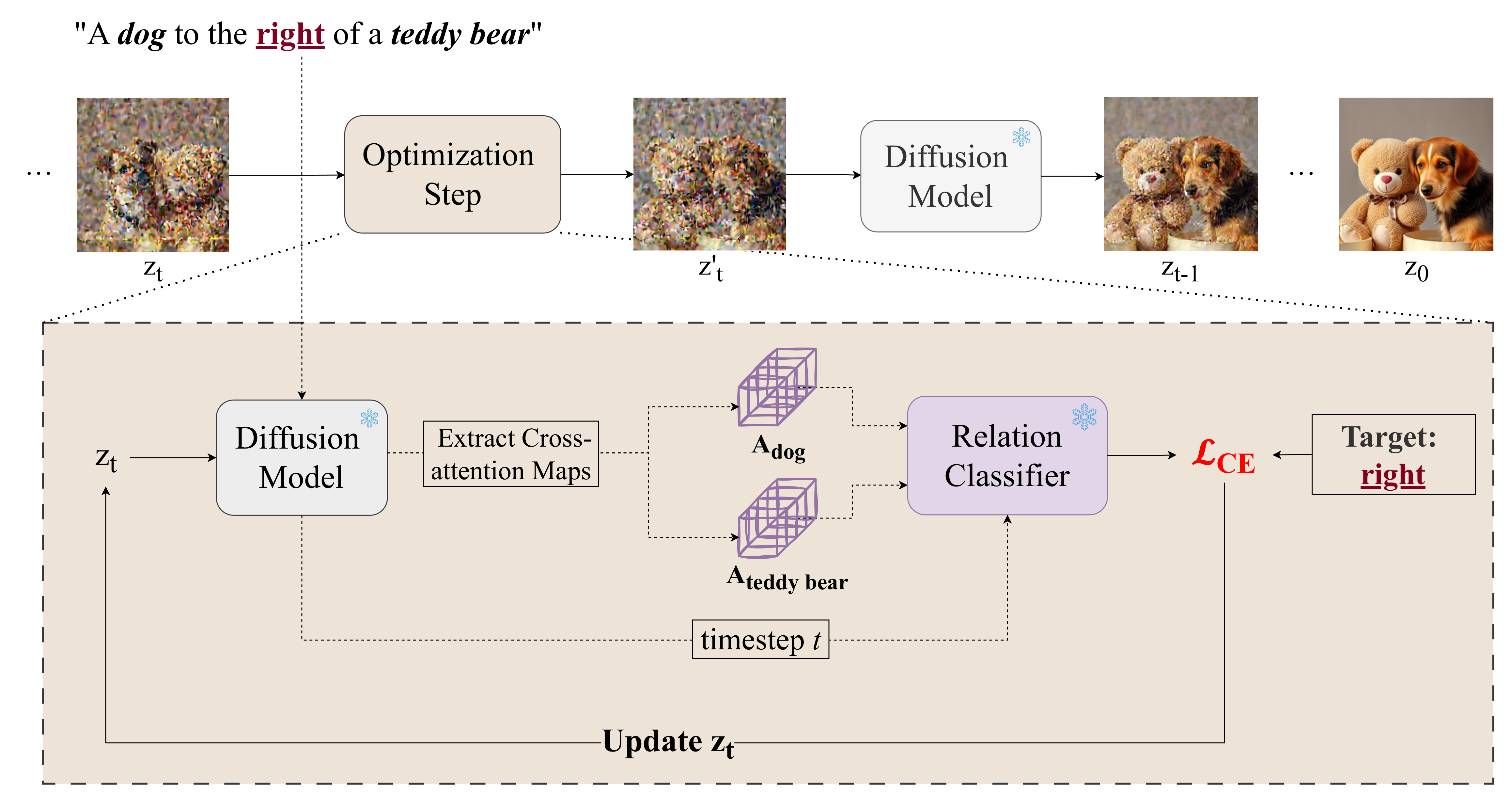
Test-time Optimization Pipeline
During inference, we extract the relevant cross-attention maps when denoising z_t and evaluate their relationship using our trained relation classifier. We then update the latent noise with backpropagation.
Training Pipeline
Given a spatially-aligned image, we perform dual image inversion (positive and negative prompts) to prevent relation leakage. During denoising, we extract the relevant attention maps and use them to train our classifier.
Test-time Optimization Pipeline
During inference, we extract the relevant cross-attention maps when denoising z_t and evaluate their relationship using our trained relation classifier. We then update the latent noise with backpropagation.
We evaluated Learn-to-Steer against handcrafted losses and other test-time optimization methods. Our method successfully generates correct spatial relationships, while other methods struggle in all of the examples.
Comparisons with all four base models.
If you find our work useful, please cite our paper:
@article{yiflach2025datadriven,
title={Data-Driven Loss Functions for Inference-Time Optimization in Text-to-Image Generation},
author={Yiflach, Sapir Esther and Atzmon, Yuval and Chechik, Gal},
journal={arXiv preprint arXiv:2509.02295},
year={2025},
}
